Caution
You're reading an old version of this documentation. If you want up-to-date information, please have a look at 0.9.1.
librosa.decompose.decompose¶
- librosa.decompose.decompose(S, n_components=None, transformer=None, sort=False, fit=True, **kwargs)[source]¶
Decompose a feature matrix.
Given a spectrogram
S, produce a decomposition intocomponentsandactivationssuch thatS ~= components.dot(activations).By default, this is done with with non-negative matrix factorization (NMF), but any
sklearn.decomposition-type object will work.- Parameters
- Snp.ndarray [shape=(n_features, n_samples), dtype=float]
The input feature matrix (e.g., magnitude spectrogram)
- n_componentsint > 0 [scalar] or None
number of desired components
if None, then
n_featurescomponents are used- transformerNone or object
If None, use
sklearn.decomposition.NMFOtherwise, any object with a similar interface to NMF should work.
transformermust follow the scikit-learn convention, where input data is(n_samples, n_features).transformer.fit_transform() will be run on
S.T(notS), the return value of which is stored (transposed) asactivationsThe components will be retrieved as
transformer.components_.T:S ~= np.dot(activations, transformer.components_).T
or equivalently:
S ~= np.dot(transformer.components_.T, activations.T)
- sortbool
If
True, components are sorted by ascending peak frequency.Note
If used with
transformer, sorting is applied to copies of the decomposition parameters, and not totransformerinternal parameters.- fitbool
If True, components are estimated from the input
S.If False, components are assumed to be pre-computed and stored in
transformer, and are not changed.- kwargsAdditional keyword arguments to the default transformer
- Returns
- components: np.ndarray [shape=(n_features, n_components)]
matrix of components (basis elements).
- activations: np.ndarray [shape=(n_components, n_samples)]
transformed matrix/activation matrix
- Raises
- ParameterError
if
fitis False and notransformerobject is provided.
See also
sklearn.decompositionSciKit-Learn matrix decomposition modules
Examples
Decompose a magnitude spectrogram into 32 components with NMF
>>> y, sr = librosa.load(librosa.ex('choice'), duration=5) >>> S = np.abs(librosa.stft(y)) >>> comps, acts = librosa.decompose.decompose(S, n_components=8)
Sort components by ascending peak frequency
>>> comps, acts = librosa.decompose.decompose(S, n_components=16, ... sort=True)
Or with sparse dictionary learning
>>> import sklearn.decomposition >>> T = sklearn.decomposition.MiniBatchDictionaryLearning(n_components=16) >>> scomps, sacts = librosa.decompose.decompose(S, transformer=T, sort=True)
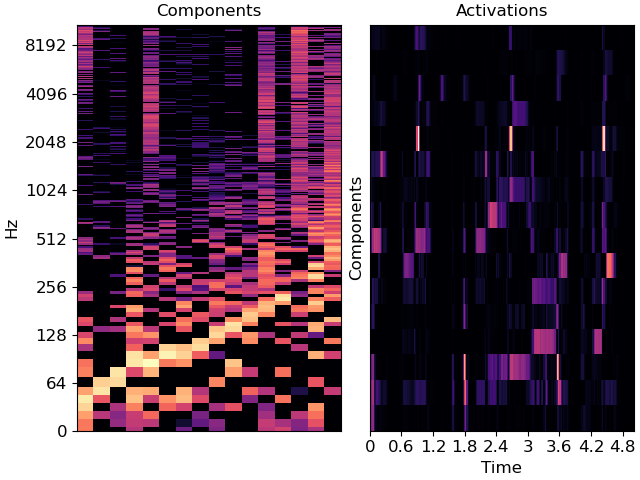
>>> import matplotlib.pyplot as plt >>> fig, ax = plt.subplots(nrows=1, ncols=2) >>> librosa.display.specshow(librosa.amplitude_to_db(comps, ... ref=np.max), ... y_axis='log', ax=ax[0]) >>> ax[0].set(title='Components') >>> librosa.display.specshow(acts, x_axis='time', ax=ax[1]) >>> ax[1].set(ylabel='Components', title='Activations')
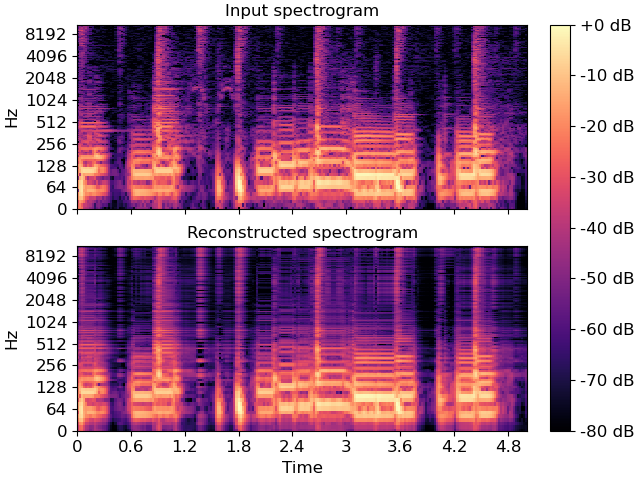
>>> fig, ax = plt.subplots(nrows=2, sharex=True, sharey=True) >>> librosa.display.specshow(librosa.amplitude_to_db(S, ref=np.max), ... y_axis='log', x_axis='time', ax=ax[0]) >>> ax[0].set(title='Input spectrogram') >>> ax[0].label_outer() >>> S_approx = comps.dot(acts) >>> img = librosa.display.specshow(librosa.amplitude_to_db(S_approx, ... ref=np.max), ... y_axis='log', x_axis='time', ax=ax[1]) >>> ax[1].set(title='Reconstructed spectrogram') >>> fig.colorbar(img, ax=ax, format="%+2.f dB")