Caution
You're reading the documentation for a development version. For the latest released version, please have a look at 0.11.0.
Note
Go to the end to download the full example code.
Vocal separation
This notebook demonstrates a simple technique for separating vocals (and other sporadic foreground signals) from accompanying instrumentation.
Warning
This example is primarily of historical interest, and we do not recommend this as a competitive method for vocal source separation. For a more recent treatment of vocal and music source separation, please refer to Open Source Tools & Data for Music Source Separation [1].
This is based on the “REPET-SIM” method of Rafii and Pardo, 2012 [2], but includes a couple of modifications and extensions:
FFT windows overlap by 1/4, instead of 1/2
Non-local filtering is converted into a soft mask by Wiener filtering. This is similar in spirit to the soft-masking method used by Fitzgerald, 2012 [3], but is a bit more numerically stable in practice.
# Code source: Brian McFee
# License: ISC
##################
# Standard imports
import numpy as np
import matplotlib.pyplot as plt
from IPython.display import Audio
import librosa
Load an example with vocals.
y, sr = librosa.loadx('fishin', duration=120)
# And compute the spectrogram magnitude and phase
S_full, phase = librosa.magphase(librosa.stft(y))
# Play back a 5-second excerpt with vocals
Audio(data=y[10*sr:15*sr], rate=sr)
Plot a 5-second slice of the spectrum
idx = slice(*librosa.time_to_frames([10, 15], sr=sr))
fig, ax = plt.subplots()
img = librosa.display.specshow(S_full[:, idx], vscale='dBFS',
y_axis='log', x_axis='time', sr=sr, ax=ax)
librosa.display.colorbar_db(img)
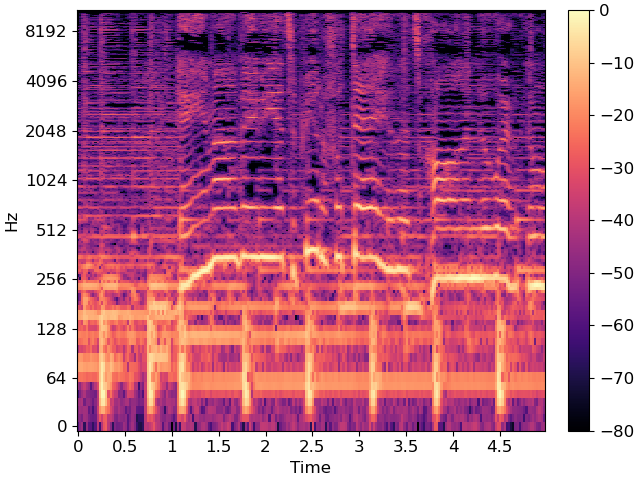
The wiggly lines above are due to the vocal component. Our goal is to separate them from the accompanying instrumentation.
# We'll compare frames using cosine similarity, and aggregate similar frames
# by taking their (per-frequency) median value.
#
# To avoid being biased by local continuity, we constrain similar frames to be
# separated by at least 2 seconds.
#
# This suppresses sparse/non-repetetitive deviations from the average spectrum,
# and works well to discard vocal elements.
S_filter = librosa.decompose.nn_filter(S_full,
aggregate=np.median,
metric='cosine',
width=int(librosa.time_to_frames(2, sr=sr)))
# The output of the filter shouldn't be greater than the input
# if we assume signals are additive. Taking the pointwise minimum
# with the input spectrum forces this.
S_filter = np.minimum(S_full, S_filter)
The raw filter output can be used as a mask, but it sounds better if we use soft-masking.
# We can also use a margin to reduce bleed between the vocals and instrumentation masks.
# Note: the margins need not be equal for foreground and background separation
margin_i, margin_v = 2, 10
power = 2
mask_i = librosa.util.softmask(S_filter,
margin_i * (S_full - S_filter),
power=power)
mask_v = librosa.util.softmask(S_full - S_filter,
margin_v * S_filter,
power=power)
# Once we have the masks, simply multiply them with the input spectrum
# to separate the components
S_foreground = mask_v * S_full
S_background = mask_i * S_full
Plot the same slice, but separated into its foreground and background
# sphinx_gallery_thumbnail_number = 2
fig, ax = plt.subplots(nrows=3, sharex=True, sharey=True)
img = librosa.display.specshow(S_full[:, idx], vscale='dBFS',
y_axis='log', x_axis='time', sr=sr, ax=ax[0])
ax[0].set(title='Full spectrum')
ax[0].label_outer()
librosa.display.specshow(S_background[:, idx], vscale='dBFS',
y_axis='log', x_axis='time', sr=sr, ax=ax[1])
ax[1].set(title='Background')
ax[1].label_outer()
librosa.display.specshow(S_foreground[:, idx], vscale='dBFS',
y_axis='log', x_axis='time', sr=sr, ax=ax[2])
ax[2].set(title='Foreground')
librosa.display.colorbar_db(img, ax=ax)
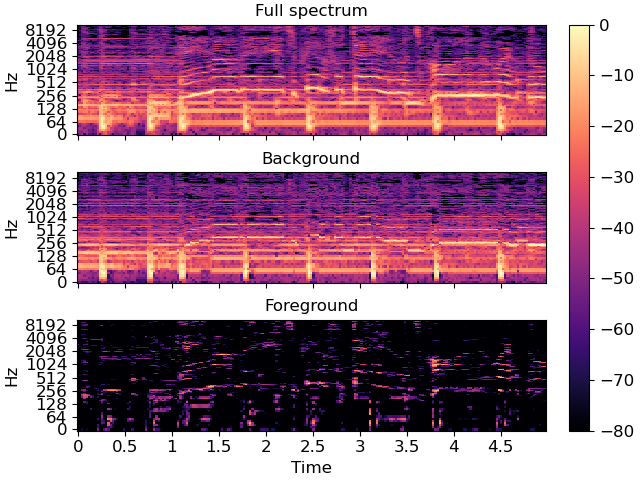
Recover the foreground audio from the masked spectrogram. To do this, we’ll need to re-introduce the phase information that we had previously set aside.
y_foreground = librosa.istft(S_foreground * phase)
# Play back a 5-second excerpt with vocals
Audio(data=y_foreground[10*sr:15*sr], rate=sr)
Total running time of the script: (0 minutes 17.800 seconds)